Dive into Deep Learning Chapter 1
Introduction
Machine learning is the study of algorithms that can learn from experience. In this book [1], it will teach you the fundamentals of machine learning, focusing in particular on Deep learning.
A Motivating Example
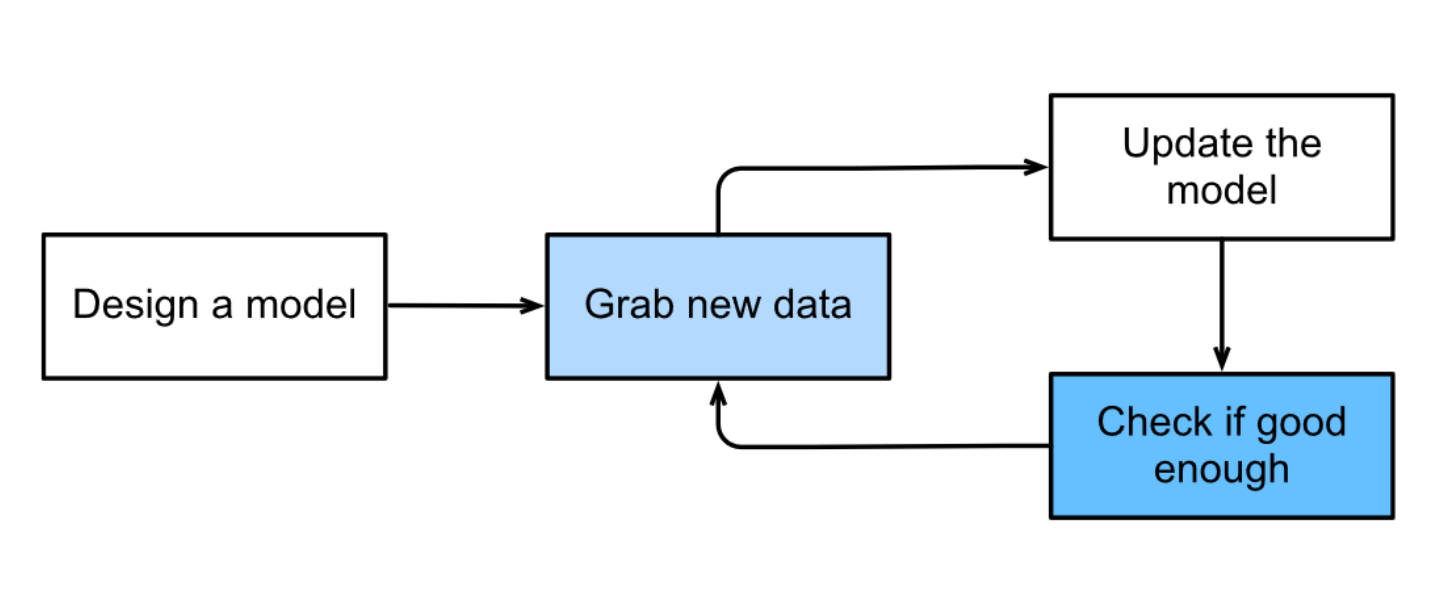
In the currently dominant approach to machine learning, we do not attempt to design a system explicitly how to map from inputs to outputs. Instead, we define a flexible program whose behavior is determined by a number of parameters. Then we use the dataset to determine the best possible parameter values, i.e., those that improve the performance of our program with respect to a chosen performance measure.
We can think of the parameters as knobs that we can turn, manipulating the behavior of the program. Once the parameters are fixed, we call the program a model. The set of all distinct programs (input–output mappings) that we can produce just by manipulating the parameters is called a family of models. And the “meta-program” that uses our dataset to choose the parameters is called a learning algorithm.
Before we can go ahead and engage the learning algorithm, we have to define the problem precisely, pinning down the exact nature of the inputs and outputs, and choosing an appropriate model family.
In machine learning, the learning is the process by which we discover the right setting of the knobs for coercing the desired behavior from our model. In other words, we train our model with data.
Deep learning is just one among many popular methods for solving machine learning problems.
Key Components
- The data that we can learn from.
- A model of how to transform the data.
- An objective function that quantifies how well (or badly) the model is doing.
- An algorithm to adjust the model’s parameters to optimize the objective function.
Data
Generally, we are concerned with a collection of examples. They should follow independently and identically distributed, (i.i.d). In order to work with data usefully, we typically need to come up with a suitable numerical representation. Each example (or data point, data instance, sample) typically consists of a set of attributes called features (sometimes called covariates or inputs)
When every example is characterized by the same number of numerical features, we say that the inputs are fixed-length vectors and we call the (constant) length of the vectors the dimensionality of the data. However, not all data can easily be represented as fixed-length vectors.
One major advantage of deep learning over traditional methods is that models can handle varying-length data. However, many of the most exciting models in deep learning do not work without large datasets. Some others might work in the small data regime, but are no better than traditional approaches.
Finally, it is not enough to have lots of data and to process it cleverly. We need the right data. One commonly occurring failure model concerns datasets where some groups of sample are unrepresented in the training data. Failure can also occur when the data does not only under-represent some groups but reflects societal prejudices. In other words, the model’s end result reflects our human being.
Models
By model, we denote the computational machinery for ingesting data of one type, and spitting out predictions of a possibly different type. In particular, we are interested in statistical models that can be estimated from data. Deep learning is differentiated from classical approaches principally by the set of powerful models that it focuses on. These models consist of many successive transformations of the data that are chained together top to bottom, thus the name deep learning.
Objective Functions
In order to develop a formal mathematical system of learning machines, we need to have formal measures of how good (or bad) our models are. In machine learning, and optimization more generally, we call these objective functions. By convention, we usually define objective functions so that lower is better. Therefore these functions are sometimes called loss functions.
When a model performs well on the training set but fails to generalize to unseen data, we say that it is overfitting to the training data.
Optimization Algorithms
Once we have got some data source and representation, a model, and a well-defined objective function, we need an algorithm capable of searching for the best possible parameters for minimizing the loss function. Popular optimization algorithms for deep learning are based on an approach called gradient descent.
Kinds of Machine Learning Problems
Supervised Learning
Supervised learning describes tasks where we are given a dataset containing both features and labels and asked to produce a model that predicts the labels when given input features. Each feature–label pair is called an example.